I'm back with the latest updates on what's hot in observability.
The response across the region to our earlier conversations around AI-based troubleshooting, runtime security, and digital experience observability has been overwhelming. Many of you have already started pilot programs, and the feedback has been exceptional.
Over the last two months, I've spent a lot of time with technology leaders, SRE teams, platform engineers, and application owners across ASEAN. Three themes keep coming up in almost every conversation:
- Defending applications against AI-generated exploits and runtime attacks
- Reducing operational load through AI-assisted incident response
- Understanding customer behaviour and business impact in mobile-first environments
What stands out to me is that these are no longer future-looking discussions. Teams are actively trying these capabilities now and starting to operationalize them.
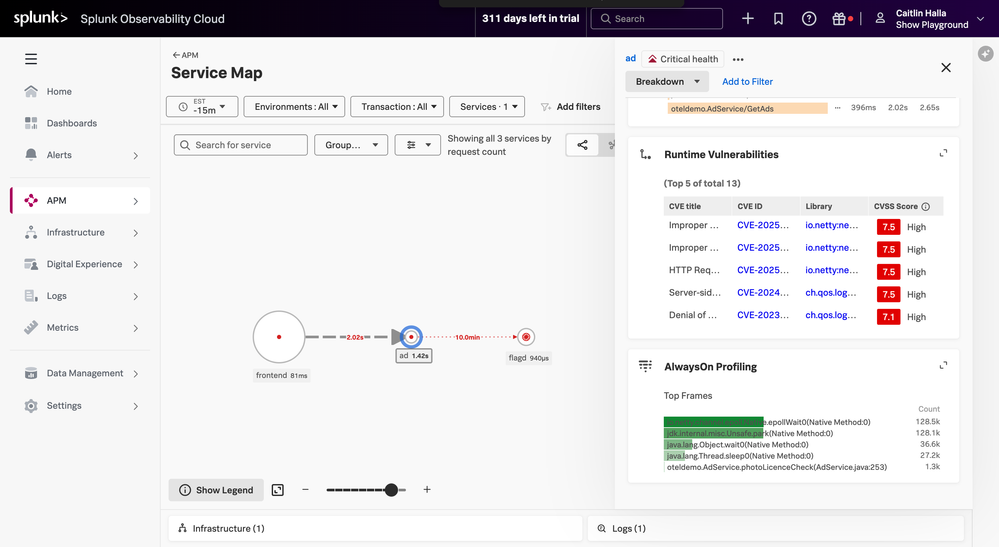
Runtime Security in the Age of AI-Generated Code
The software landscape has changed dramatically. In 2025, 41% of all code written globally was AI-generated, and we are on track to exceed 50% by 2027. While this accelerates development velocity, it also introduces a serious security challenge: AI-generated code contains up to 2.74x more security defects compared to human-written code.
At the same time, the time between vulnerability disclosure and active exploitation keeps shrinking.
This is why so many teams I speak with are focusing on runtime visibility and active protection, not just detection after the fact. When an attack happens, they don't want another alert sitting in a queue. They want immediate context and the ability to respond or block in real time.
With Splunk Secure Application, teams can now see:
- The attacked host, environment, and service
- Impacted business workflows
- Client IP and HTTP method
- Full code-level stack traces
- The exact vulnerability being exploited
Teams can also define policies to monitor or actively block attack types such as Command Execution, Log4j, SQL Injection, or unauthorized network access. Most customers I speak with start in monitor mode first so they can validate detections before enabling enforcement in production.
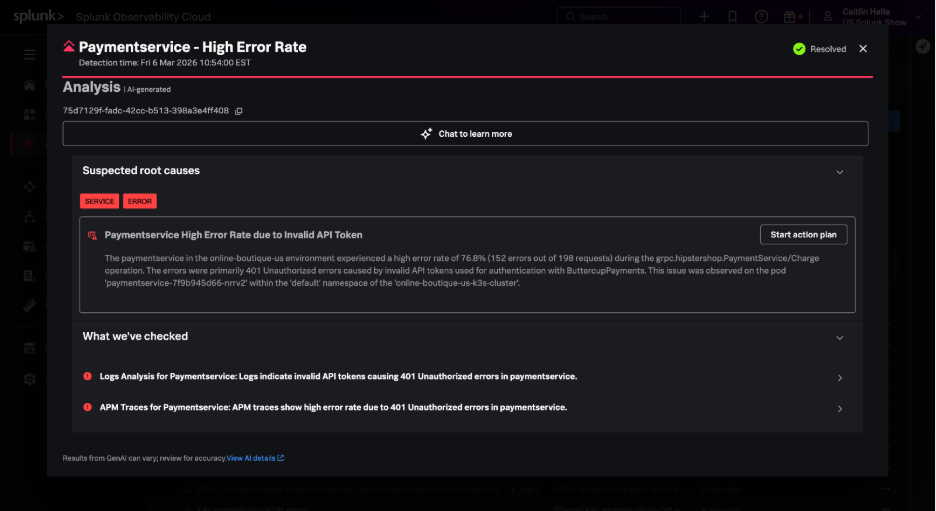
AI Agents as the First Responder for Incidents
One challenge comes up in almost every operational discussion I have with NOC and SRE teams: there is simply too much telemetry, too many alerts, and too much manual effort spent trying to piece incidents together under pressure.
What has changed recently is the quality of the AI models and how effectively they can work across observability data.
I'm now seeing teams seriously evaluate AI troubleshooting agents as a first responder for production incidents. The real value isn't just the model itself — it's the ability to aggregate and correlate metrics, traces, logs, and events across the environment quickly enough to help engineers during the incident, not after it.
With Splunk's AI Troubleshooting Agent, when an alert fires the agent immediately begins investigating and presents:
- A summary of the incident
- Suspected root causes with supporting evidence
- Cross-layer impact analysis
- Recommended remediation actions
- Human-in-the-loop escalation when needed
The operational benefits are becoming very real:
- L1 support teams get actionable context immediately and reduce escalations
- SREs spend less time on repetitive triage work
- Developers receive service-level context tied directly to incidents
- Service owners gain a clearer understanding of business impact
I'm running enablement sessions throughout May for teams interested in piloting these capabilities. Let me know if you'd like to schedule time.
Digital Experience Analytics and Customer Behaviour
Traditional observability platforms are very good at telling teams when applications are slow or unavailable. What they often fail to show is how those technical issues affect customer behaviour and business outcomes.
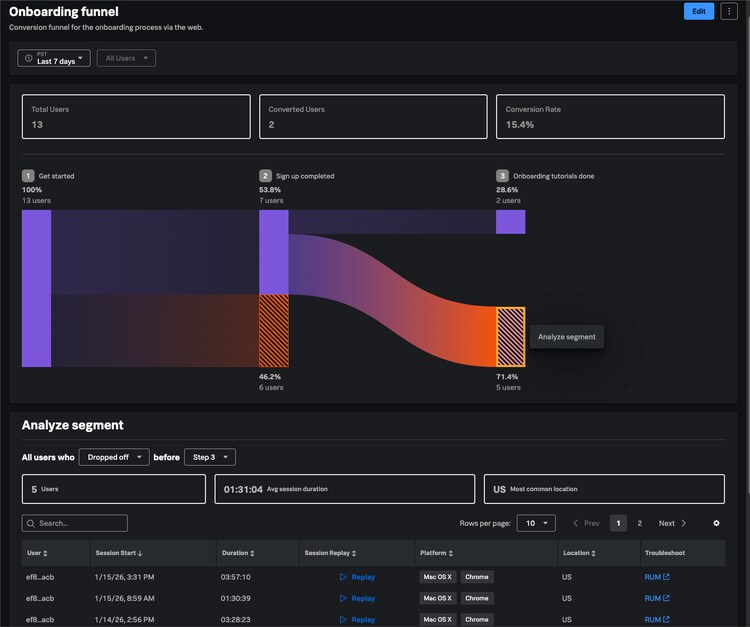
This conversation comes up constantly with digital teams running customer-facing mobile and web applications across APAC.
Many organizations can already measure latency and uptime. Fewer can clearly explain why users abandon onboarding flows, stop transactions midway, or disengage from specific application journeys.
This is where Digital Experience Analytics is getting a lot of attention. Teams can now use:
- User Journey Maps to visualize how users move through applications
- Conversion Funnels to identify abandonment points across key workflows
- Session Replay to see exactly what users experienced before dropping off
What I find most interesting is how this changes engineering prioritization. Product teams can correlate conversion drop-offs with technical issues. Engineering teams can prioritize fixes based on customer and business impact, not just infrastructure severity.
Several FSI organizations in Singapore and government agencies across ASEAN have told me this fundamentally changes how they think about digital experience optimization.
---
Want to go deeper on any of these? I'm running hands-on enablement sessions across May and June for teams looking to pilot runtime security, AI incident response, or digital experience analytics. Reach out and let's get something on the calendar.